library(ggplot2)
library(palmerpenguins)
penguins <- na.omit(palmerpenguins::penguins)Tidy Data Visualization: ggplot2 vs seaborn
R
Python
Visualization
A comparison of two popular data visualization tools for R and Python
ggplot2 is based on Leland Wilkinson”s Grammar of Graphics, a set of principles for creating consistent and effective statistical graphics, and was developed by Hadley Wickham. The package is a cornerstone of the R community and integrates seamlessly with other tidyverse packages. One of the key strengths of ggplot2 is its use of a consistent syntax, making it relatively easy to learn and enabling users to create a wide range of graphics with a common set of functions. The package is also highly customizable, allowing detailed adjustments to almost every element of a plot.
seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. Key features of seaborn include its ability to work well with pandas data frames, built-in themes for styling matplotlib graphics, and functions for visualizing distributions.
The types of plots that I chose for the comparison heavily draw on the examples given in R for Data Science - an amazing resource if you want to get started with data visualization.
Loading packages and data
We start by loading the main packages of interest and the popular penguins data that comes with seaborn and exists as an R package. We then use the penguins data frame as the data to compare all functions and methods below. Note that I drop all rows with missing values because I don’t want to get into related messages in this post.
import seaborn as sns
penguins = sns.load_dataset("penguins")
sns.set_theme(style = "whitegrid")A full-blown example
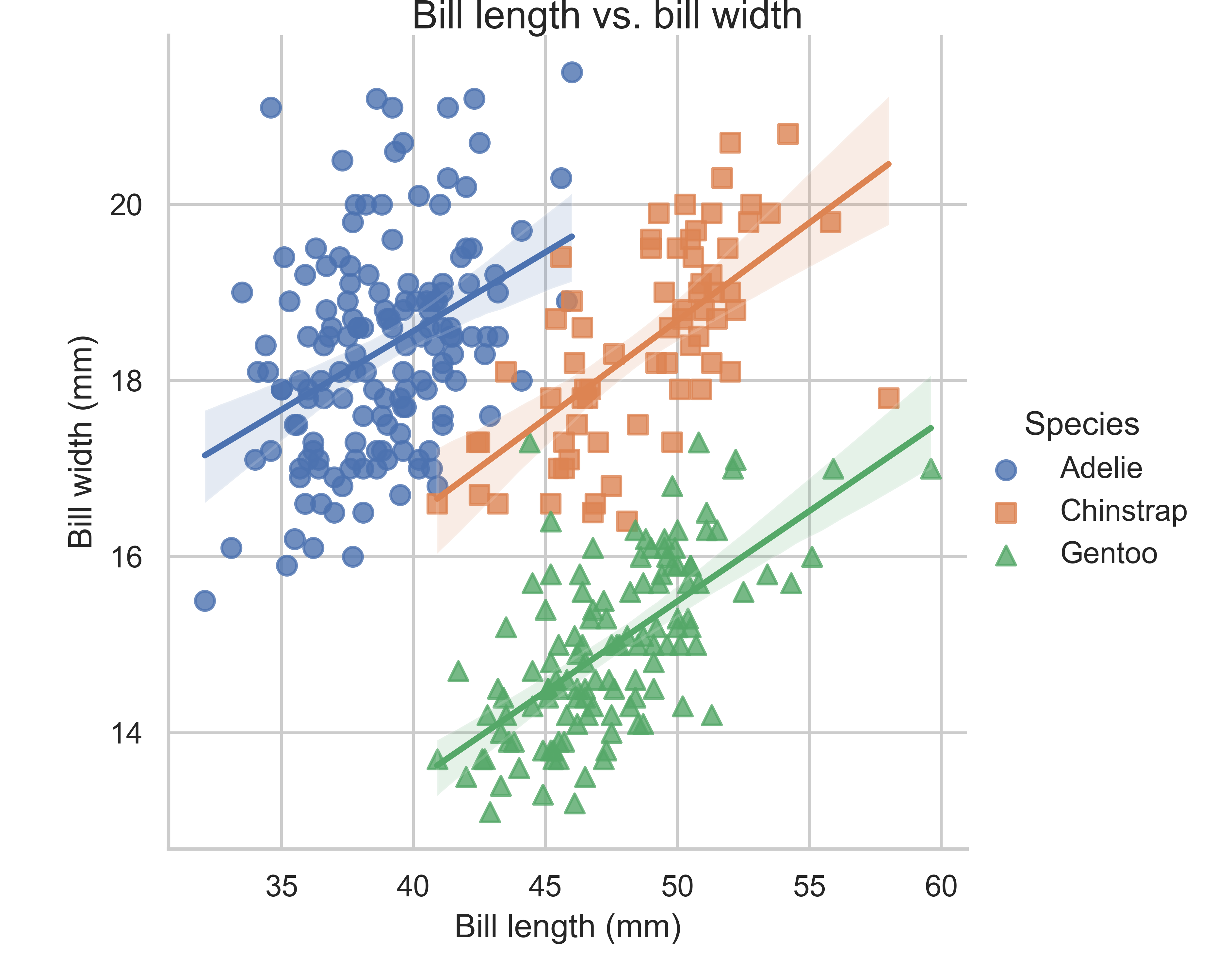
Let”s start with an advancved example that combines many different aesthetics at the same time: we plot two columns against each other, use color and shape aesthetics do differentiate species, include separate regression lines for each species, manually set nice labels, and use a theme. As you can see in this example already, ggplot2 and seaborn have a fundamentally different syntactic approach. While ggplot2 works with layers, seaborn uses a specific function with a few parameter and additional methods.
ggplot(penguins,
aes(x = bill_length_mm, y = bill_depth_mm,
color = species, shape = species)) +
geom_point(size = 2) +
geom_smooth(method = "lm", formula = "y ~ x") +
labs(x = "Bill length (mm)", y = "Bill width (mm)",
title = "Bill length vs. bill width",
subtitle = "Using geom_point and geom_smooth of the ggplot2 package",
color = "Species", shape = "Species") +
theme_minimal()
(sns.lmplot(
data = penguins,
x = "bill_length_mm", y = "bill_depth_mm",
hue = "species", markers = ["o", "s", "^"], fit_reg = True,
scatter_kws = {"s": 50}, legend = False
)
.set_axis_labels("Bill length (mm)", "Bill width (mm)")
.add_legend(title = "Species")
.fig.suptitle("Bill length vs. bill width", y = 1)
)
Visualizing distributions
A categorical variable
Let’s break down the differences in smaller steps by focusing on simpler examples. If you have a categorical variable and want to compare its relevance in your data, then ggplot2::geom_bar() and seaborn.countplot() are your friends. I manually specify the order in the seaborn figure to mimic the automatic behavior of ggplot2.
ggplot(penguins,
aes(x = island)) +
geom_bar()
sns.countplot(
data = penguins,
x = "island",
order = sorted(penguins["island"].unique())
)
A numerical variable
If you have a numerical variable, usually histograms are a good starting point to get a better feeling for the distribution of your data. ggplot2::geom_histogram() and seaborn.histplot with options to control bin widths or number of bins are the functions for this task.
ggplot(penguins,
aes(x = bill_length_mm)) +
geom_histogram(binwidth = 2)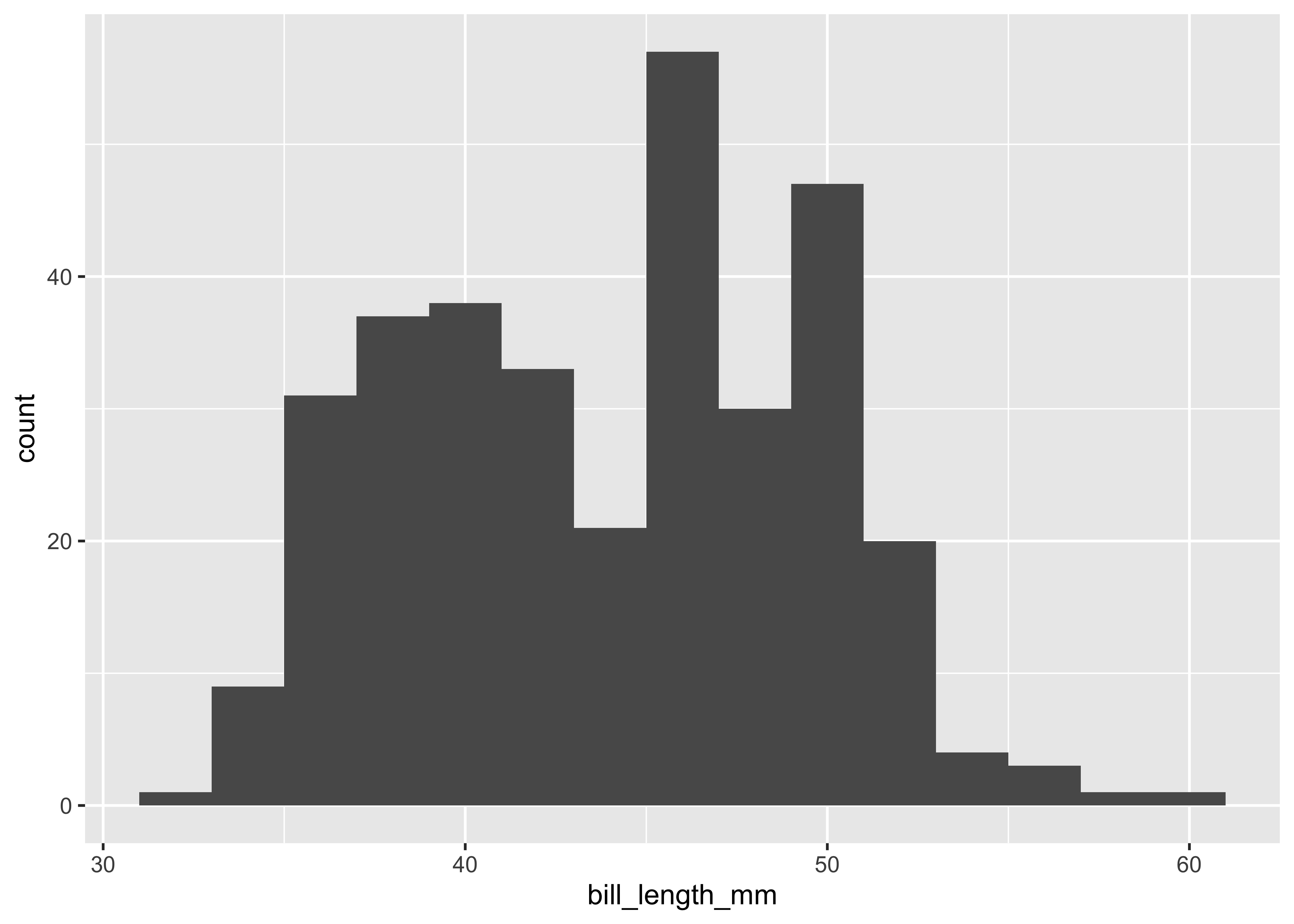
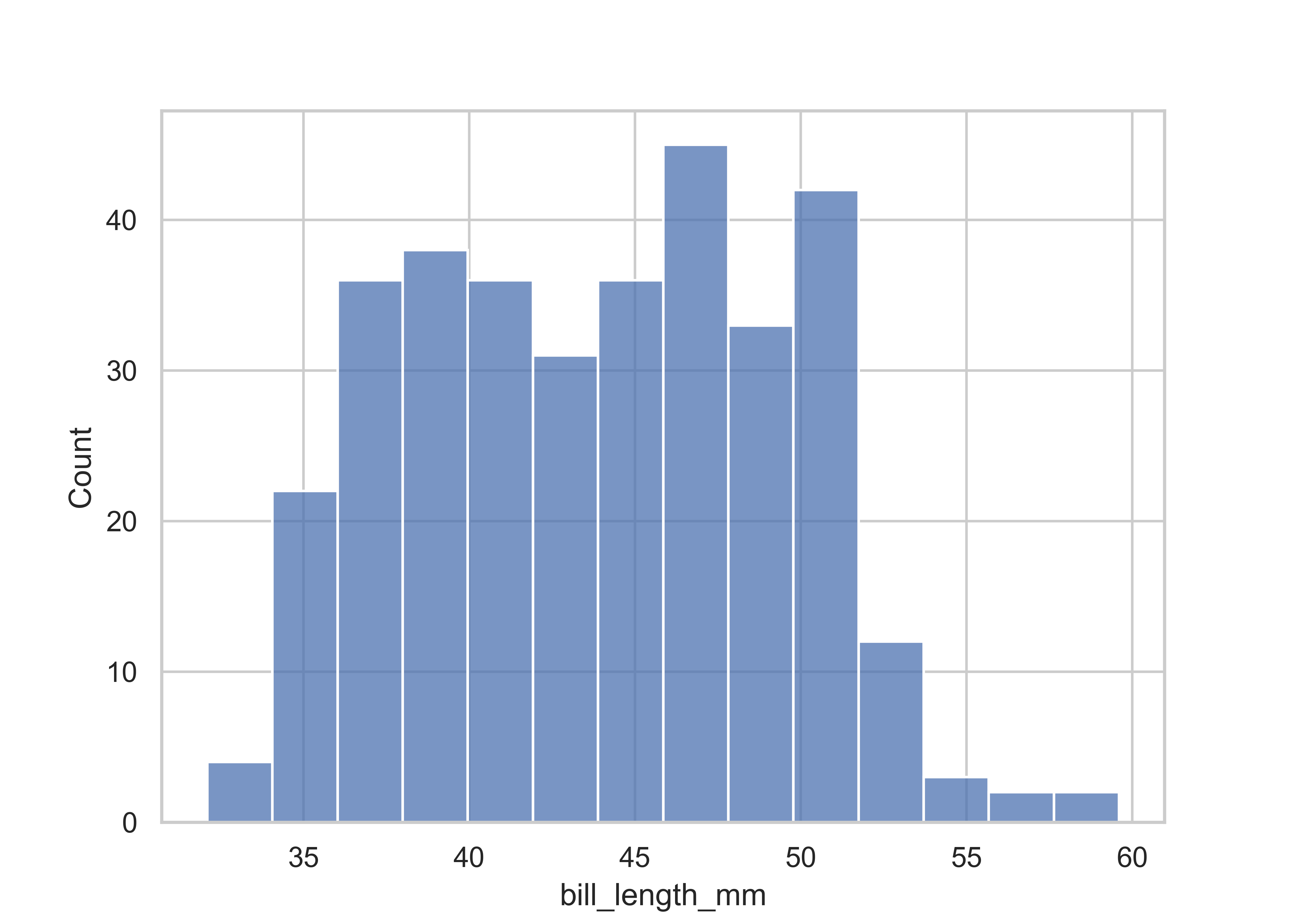
sns.histplot(
data = penguins,
x = "bill_length_mm",
binwidth = 2
)
Both packages also support density curves, but I personally wouldn”t recommend to start with densities because they are estimated curves that might obscure underlying data features. However, we look at densities in the next section.
Visualizing relationships
A numerical and a categorical variable
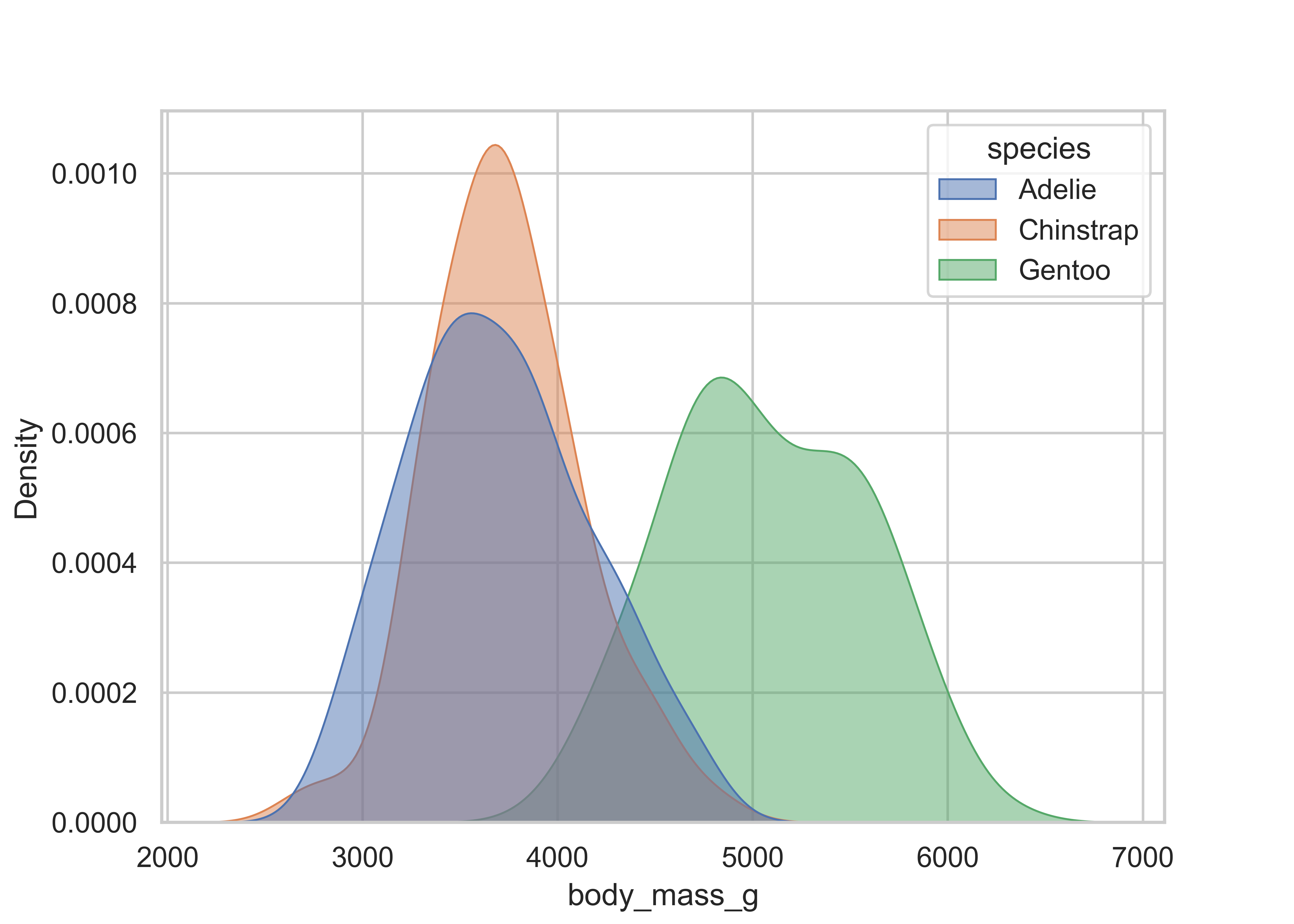
To visualize relationships, you need to have at least two columns. If you have a numerical and a categorical variable, then histograms or densities with groups are a good starting point. The next example illustrates the use of density curves via ggplot2::geom_density() and seaborn.kdeplot() with similar options to control the appearance.
ggplot(penguins,
aes(x = body_mass_g, color = species, fill = species)) +
geom_density(linewidth = 0.75, alpha = 0.5)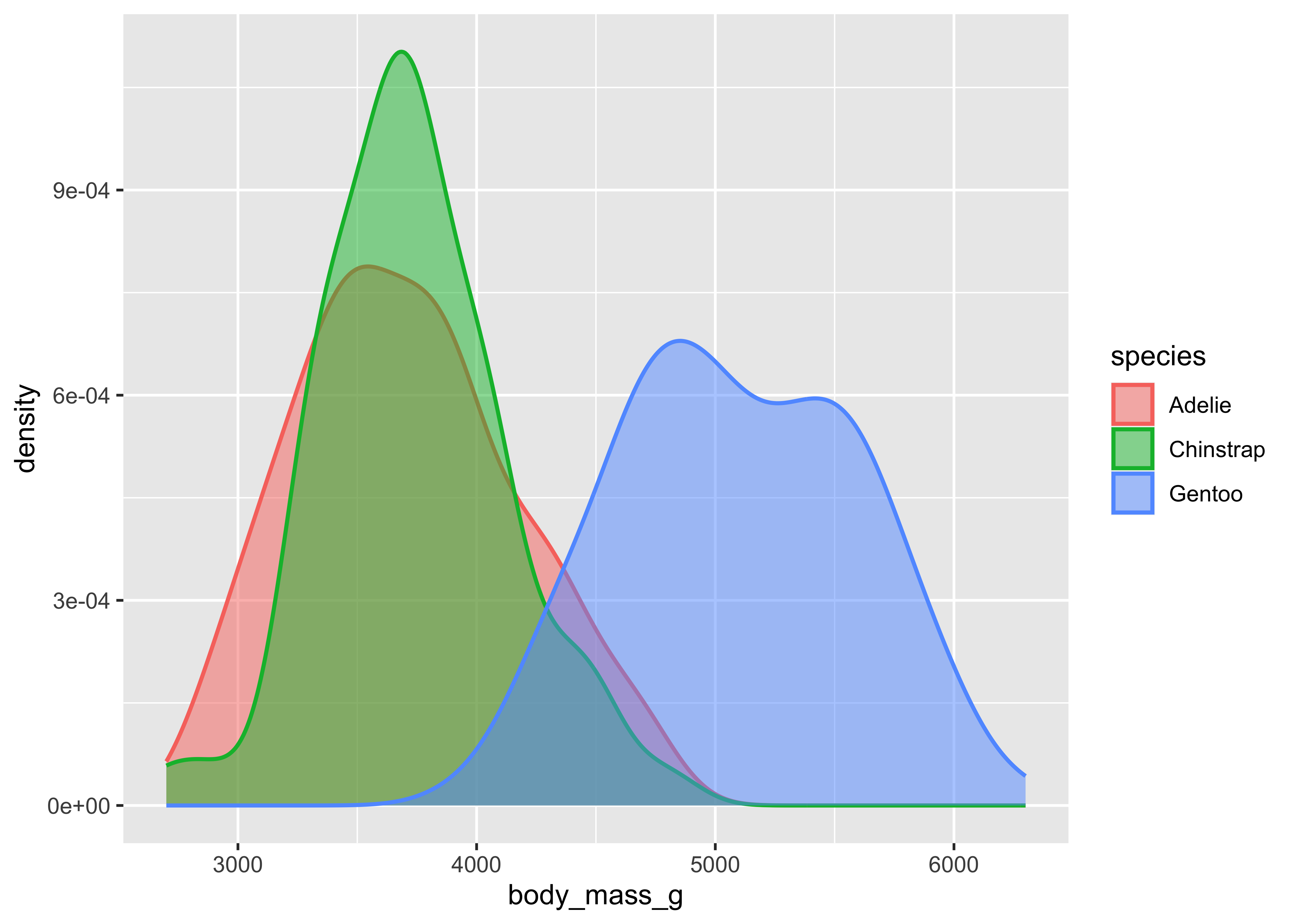
sns.kdeplot(
data = penguins,
x = "body_mass_g",
hue = "species",
fill = True, common_norm = False, alpha = 0.5, linewidth = 0.75
)
Two categorical columns
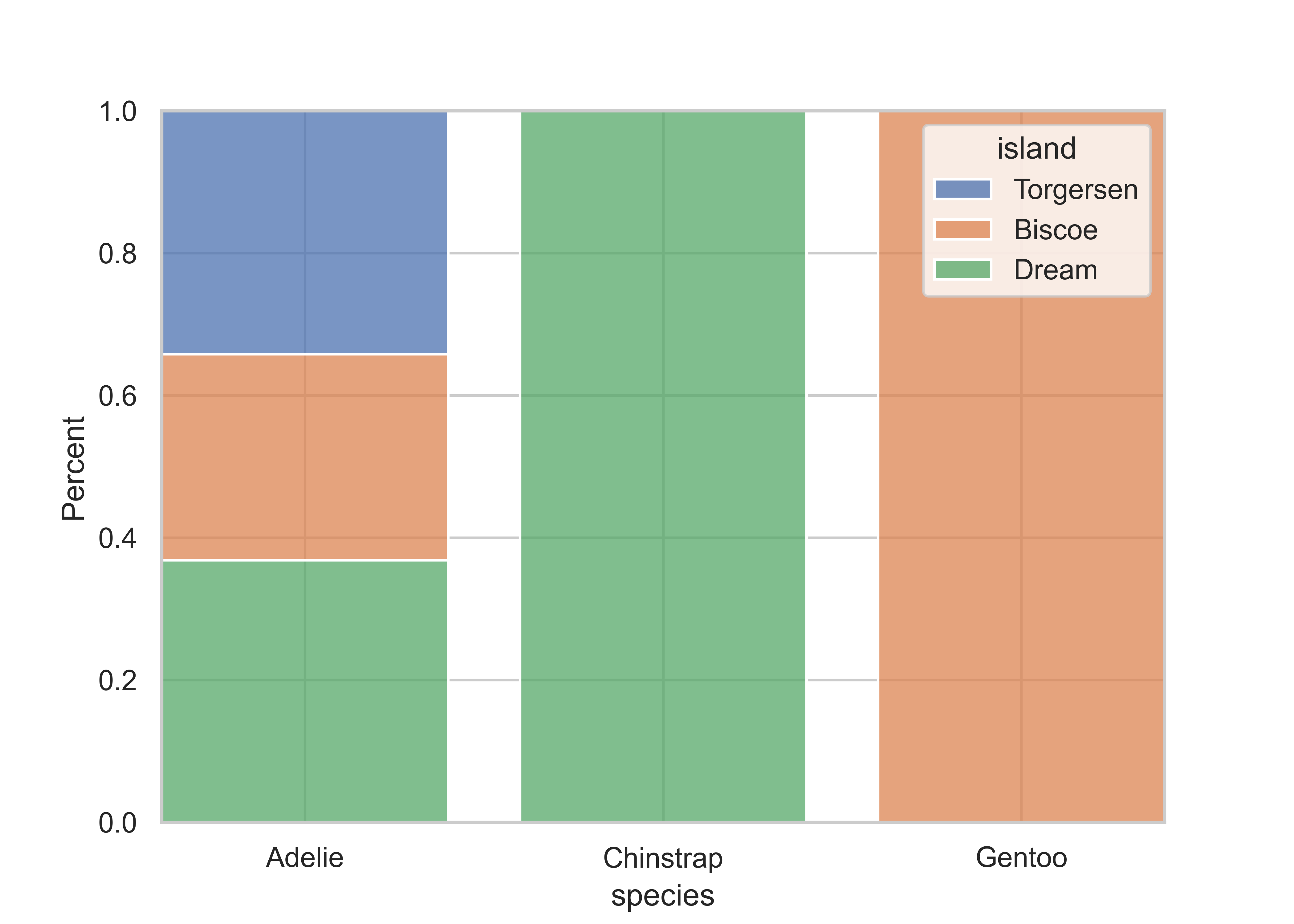
Stacked bar plots are a good way to display the relationship between two categorical columns. geom_bar() with the position argument and seaborn.histplot() with stat are your aesthetics of choice for this task. Note that you can easily switch to counts by using position = "identity" and stat = "count", respectively, instead of relative frequencies as in the example below. Note that I use shrink = 0.8 to get some spacing between columns in the seaborn plot.
ggplot(penguins, aes(x = species, fill = island)) +
geom_bar(position = "fill")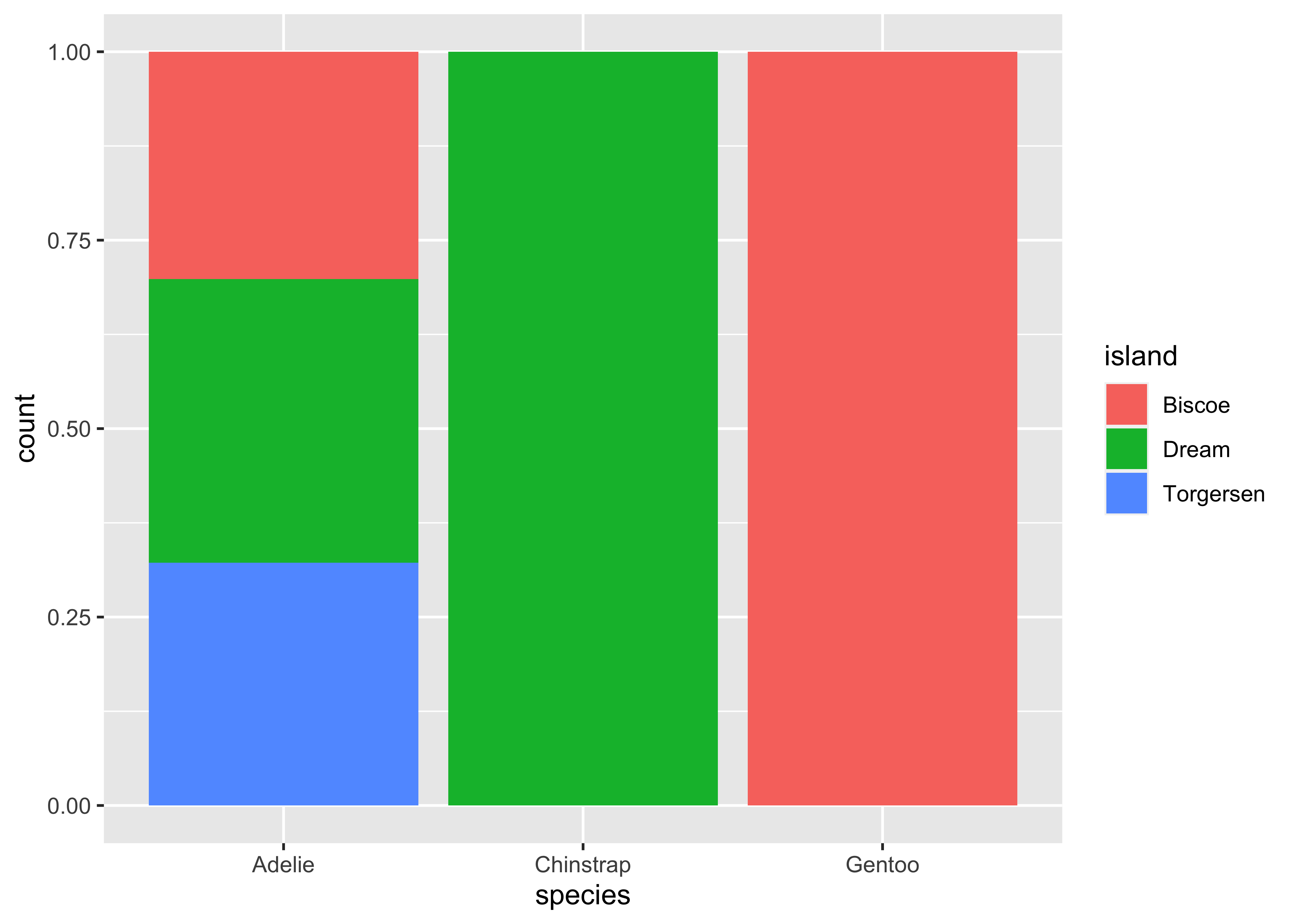
sns.histplot(
data = penguins,
x = "species",
hue = "island", multiple = "fill", stat = "percent", shrink = 0.8
)
Two numerical columns
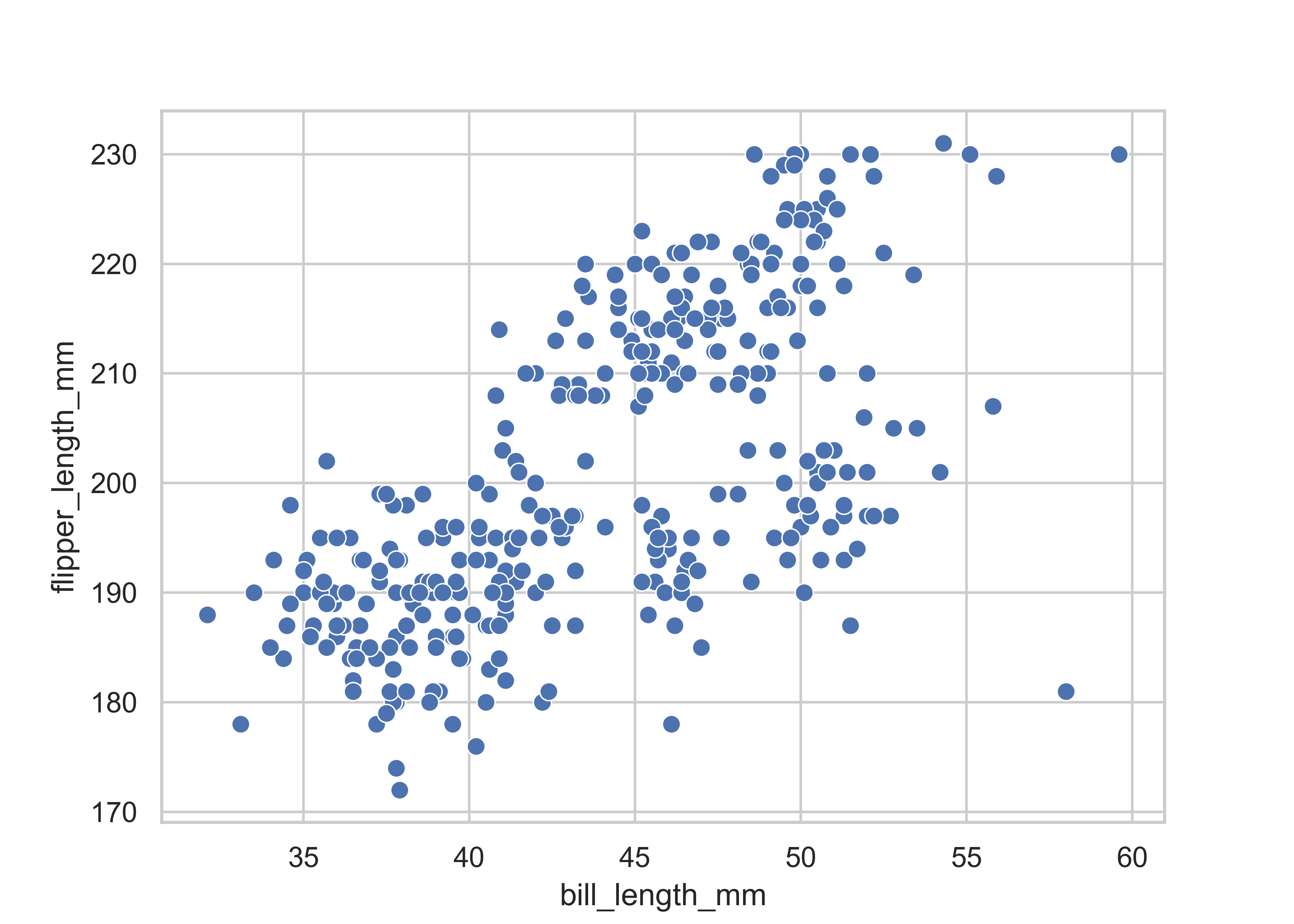
Scatter plots and regression lines are definitely the most common approach for visualizing the relationship between two numerical columns and we focus on scatter plots for this example (see the first visualization example if you want to see again how to add a regression line). Here, the size parameter controls the size of the shapes that you use for the data points in ggplot2::geom_point() relative to the base size (i.e., it is not tied to any unit of measurement like pixels). For seaborn.scatterplot() you have the s parameter to control point sizes manually, where size is typically given in squared points (where a point is a unit of measure in typography, equal to 1/72 of an inch).
ggplot(penguins,
aes(x = bill_length_mm, y = flipper_length_mm)) +
geom_point(size = 2)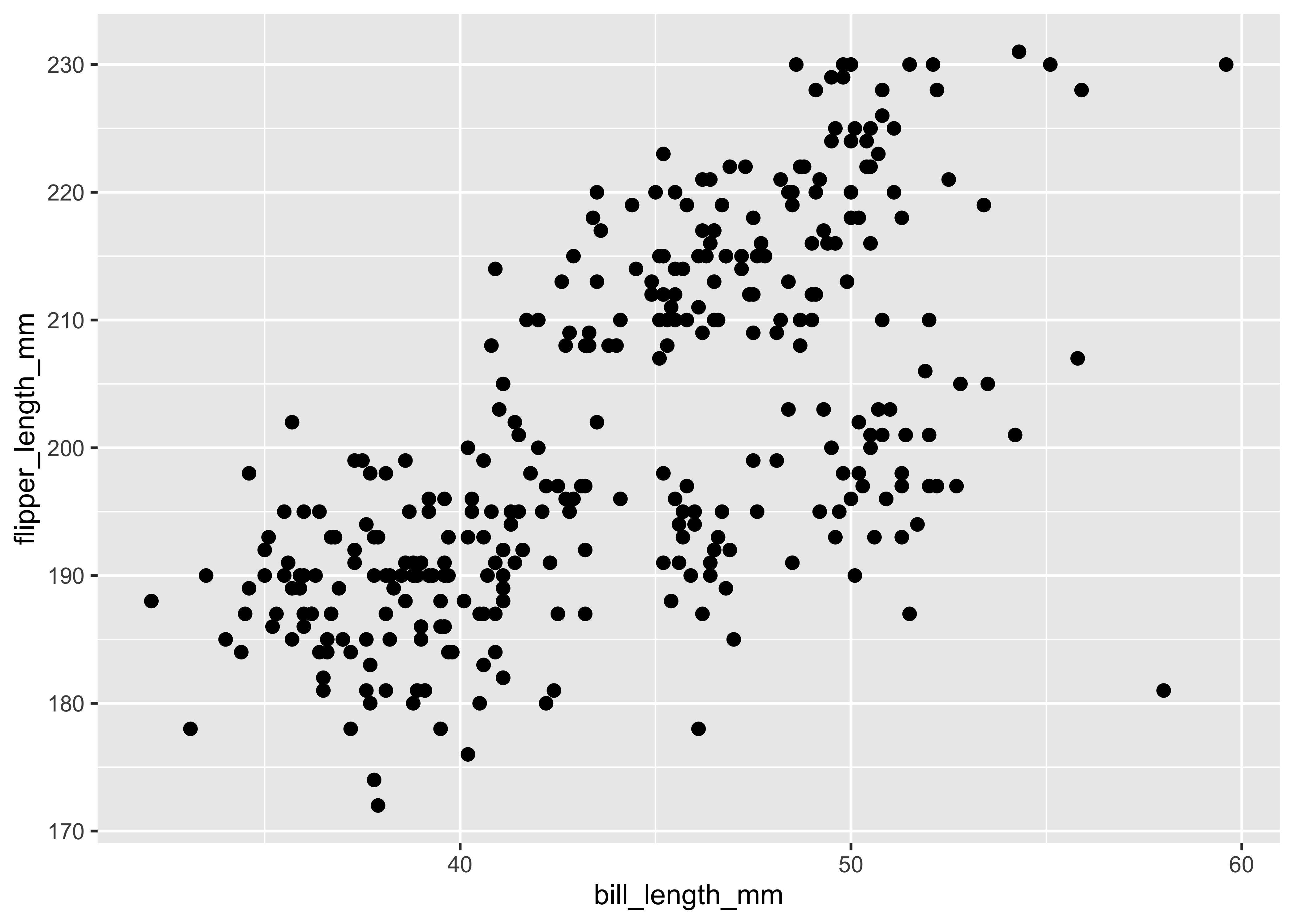
sns.scatterplot(
data = penguins,
x = "bill_length_mm", y = "flipper_length_mm",
s = 50
)
Three or more columns
You can include more information by mapping columns to additional aesthetics. For instance, we can map colors and shapes to species and create separate plots for each island by using facets. Facets are actually a great way to extend your figures, so I highly recommend playing around with them using your own data.
In ggplot2 you add the facet layer at the end, whereas in seaborn you have to start with the facet grid at the beginning and map scatter plots across facets. Note that I use variable assignment to penguins_facet in order to prevent seaborn from printing the figure twice while rendering this post (no idea why though).
ggplot(penguins,
aes(x = bill_length_mm, y = flipper_length_mm)) +
geom_point(aes(color = species, shape = species)) +
facet_wrap(~island)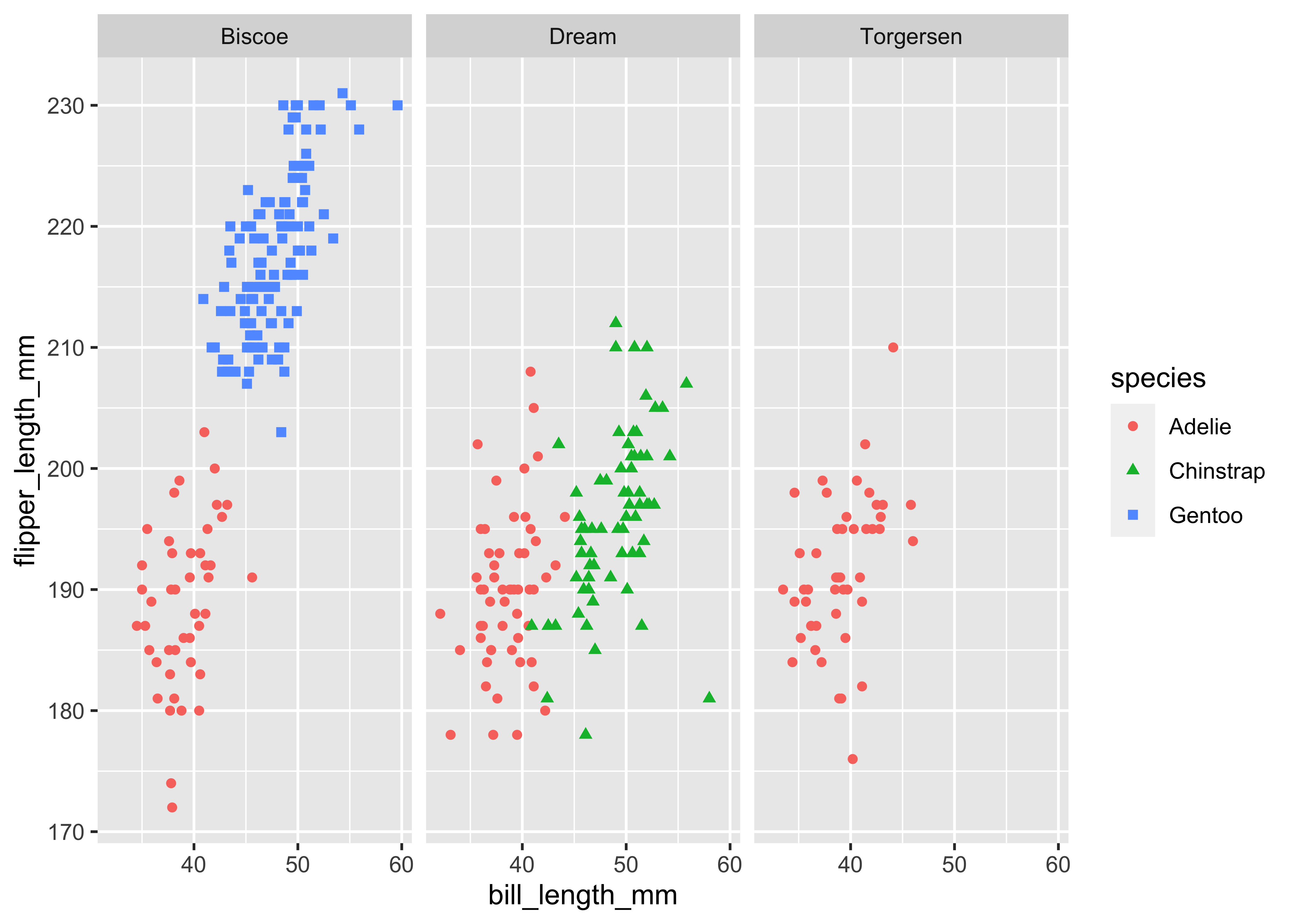
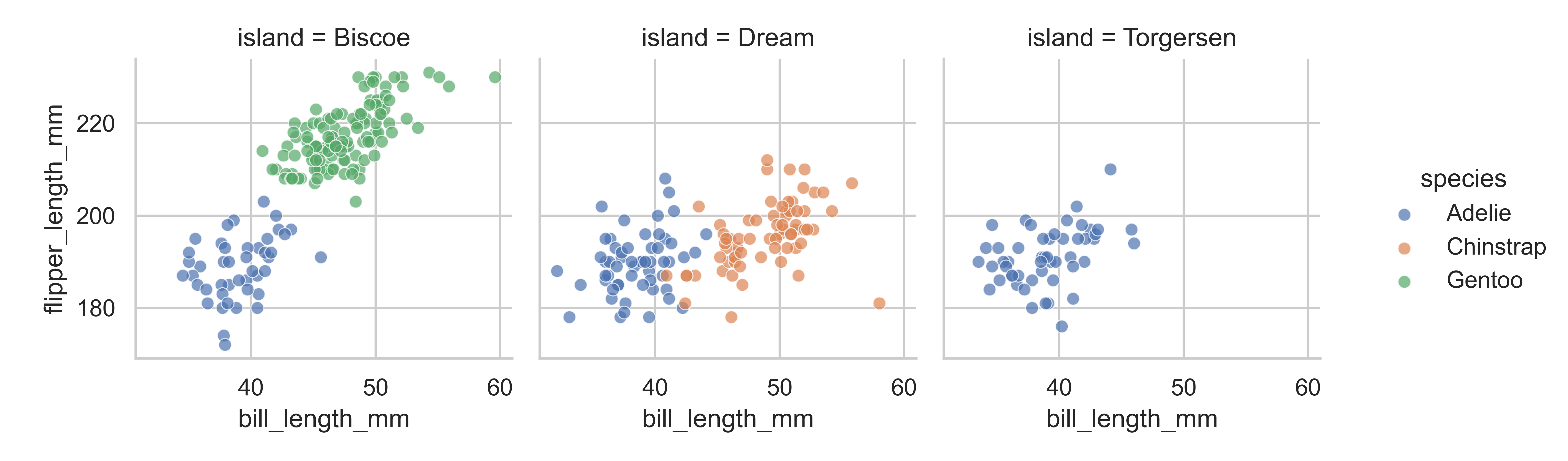
penguins_facet = (sns.FacetGrid(
data = penguins, col="island", col_order = sorted(penguins["island"].unique()),
hue="species", margin_titles = True
)
.map(sns.scatterplot, "bill_length_mm", "flipper_length_mm", alpha = 0.7)
.add_legend()
)
Saving plots
As a final comparison, let us look at saving plots. ggplot2::ggsave() provides the most important options as function paramters. In seaborn, you have to, for instance, tweak the figure size before can save the figure.
penguins_figure <- penguins |>
ggplot(aes(x = bill_length_mm, y = flipper_length_mm)) +
geom_point()
ggsave(penguins_figure, filename = "penguins-figure.png",
width = 7, height = 5, dpi = 300)penguins_figure = sns.scatterplot(
data = penguins,
x = "bill_length_mm", y = "flipper_length_mm"
)
penguins_figure.figure.set_size_inches(7, 5)
penguins_figure.figure.savefig("penguins-figure.png", dpi = 300)Conclusion
In terms of syntax, ggplot2 and seaborn are considerably different. ggplot2 follows the basic syntax of
ggplot(data = <DATA>, aes(x = <X-VAR>, y = <Y-VAR>)) +
geom_<PLOT-TYPE>() +
other_layersand seaborn follows the syntax
sns.<PLOT-FUNCTION>(data = <DATA>, x = "<X-VAR>", y = "<Y-VAR>", other_parameters).I think this difference comes from different philosophies. ggplot2 focuses on layering and mapping data to aesthetics, whereas seaborn is more about providing a variety of complex plot types easily. Moreover, ggplot2 is designed to work considerably well with tidy data (see my blog post on tidy data), while seaborn is more flexible with input data formats.
Both offer extensive customization options, but they are implemented differently. ggplot2 uses additional layers and scales and hence allows for a large ecosystem (see, for instance, this repo for a collection of links), while seaborn relies on the customization options of matplotlib and its own parameters. I think both approaches are powerful and have their unique advantages, and the choice between them often depends on your programming language preference and specific requirements of the data visualization task.